

Designing the Future of Research Publication
Designing the Future of Research Publication
A first-principles approach to scientific communication in the age of the Internet.


Our systems for science have become sclerotic, and publication might be the most broken of them all. Research papers are stuck in a 300 year old format, they get scattered across the sites of hundreds of different publishers, experiment artifacts that are needed for reproducibility have no home outside of niche third-party repositories, published literature is owned and gate-kept by an oligopoly of misaligned companies, and we’ve let our scientific record become polluted with low-quality, non-reproducible work. Many are attempting to reform this convoluted ecosystem and shift these slow-moving beasts, but could there be another way out?
History sometimes gives us an opportunity to reimagine how things are done, to rebuild from scratch with a blank slate, free from legacy constraints. The proliferation of the Internet has enabled us to do this for money, music, media and more; and we have the same opportunity to radically transform scientific publication. To do it right, we should start with a solid base, a strong grounding in truth.
Fundamentally, research publication is the medium of information exchange between scientists, and should be designed to maximize the velocity of scientific progress. But how do we define that objective?
What is Scientific Progress?
The goal is to accelerate scientific progress, but since that’s a somewhat abstract concept, let’s break it down to its principal components and figure out how we can improve those.
Science progresses when we conjecture, criticize, and achieve consensus on our shared knowledge:
Conjecture good explanations about the nature of reality
Criticize the explanations through experiment
Iterate until we achieve consensus on our knowledge1
To maximize the pace of scientific progress, we should improve the rate at which we can do these three components. Publication plays a central role here since it’s how scientists communicate their conjectures/critiques and reach consensus with each other. So how can we improve on all three components—and scientific progress more generally—by improving publication?
Computational Research Requires Computational Publication
Industrial-Age constraints are limiting the rate at which research gets shared; both in bandwidth through the archaic PDF format, and in speed through multi-month peer-review delays.
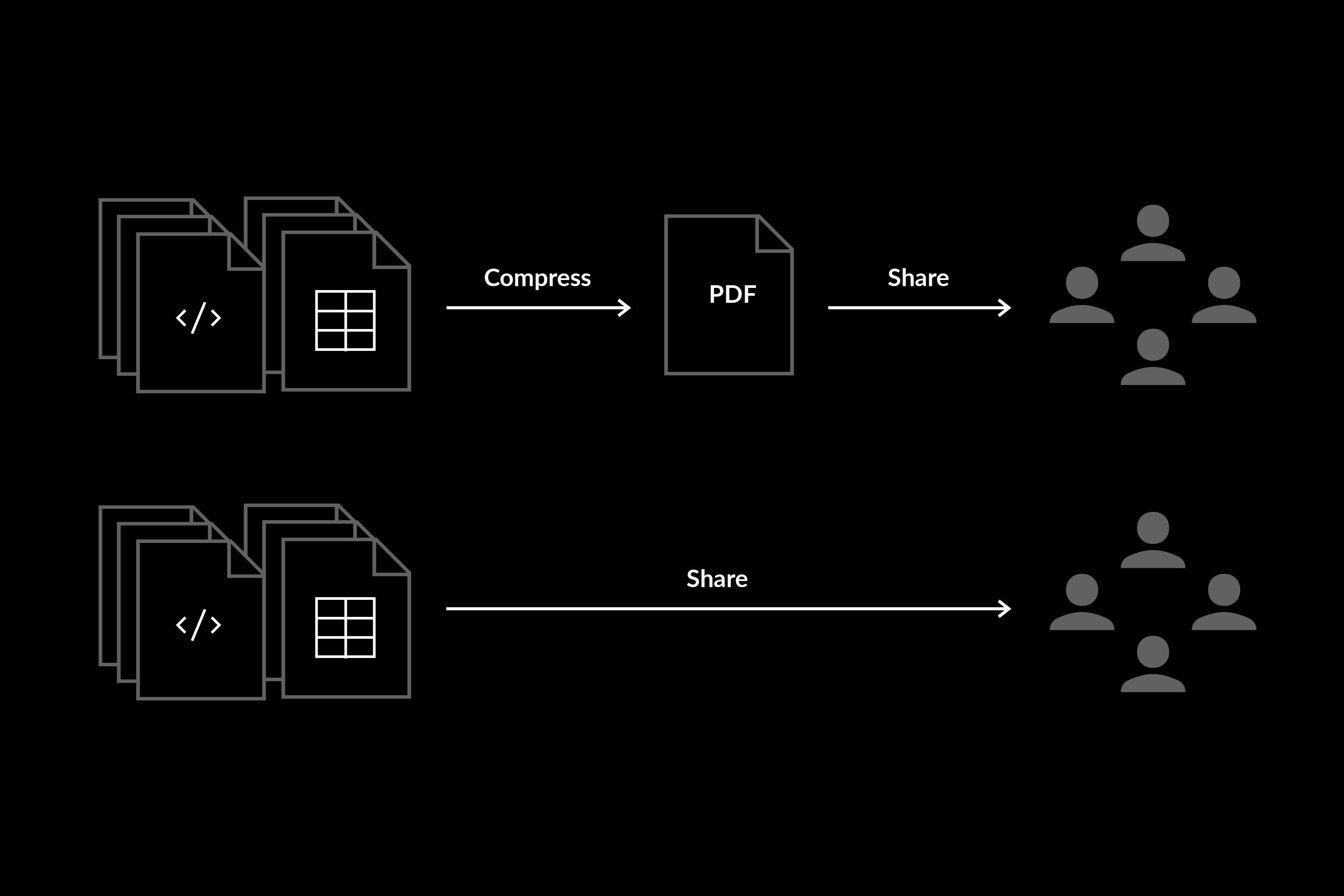
The PDF format—which worked well in the pre-internet world of physical papers—is very low bandwidth for today’s age of computational research and the Internet. PDFs lose a lot of useful scientific information because they compress research results into a static text-based format. From pure Information Theory, increasing the amount of useful experiment information that’s published improves our capacity to catch issues, criticize work, and verify results. We can achieve this by simply sharing all of the digital artifacts—code and data—when publishing research.
An even better way to publish involves more than just openly sharing code and data; it looks more like digitally reproducible research, where the code and data is loaded in an environment where anybody can easily reproduce the results, interrogate the inputs, and run their own statistical checks on the data. Why?
It improves our ability to critique and catch issues since all research artifacts are available and accessible for interrogation.
It makes it easier for others to achieve consensus on the results by reducing friction to reproducing the experiment results.
So digitally reproducible research accelerates the rate at which we can critique and achieve consensus on our scientific knowledge, and lets us evolve beyond the archaic PDF format. Another Industrial-Age concept that’s holding back progress is peer review.
Pre-publication peer-review was needed 50 years ago when the physical constraint of having to print papers meant we couldn’t publish so much work, so it was devised as a mechanism to filter out low-quality work — although now it’s just a burdensome tax on all researchers that can’t even catch bogus work. We can improve the speed at which research is shared by orders of magnitude if reviews no longer gate keep publication. Researchers should be able to just share their work online and let the reviews/replications occur post-publication.
The public good of science should be open to the public
Barriers and gatekeepers inhibit progress, they limit our capacity to ask and answer—conjecture and critique—scientific questions. To improve how research is shared, we should remove the notion of paywalls and prestige, and make it easier to share new ideas and collaborate on solving tough scientific problems.
Anyone who’s interacted with research realizes that paywalls are needless barriers based on archaic business models. They’re an obvious problem and should be eliminated to enable more people to participate in and contribute to science.
Prestige barriers are less discussed but just as harmful. There’s a growing cohort of Internet-educated and internationally-educated scientists who are capable of contributing, are genuinely curious, and may have useful, non-consensus ideas, but are blocked out because they don’t have the name of a prestigious institute, a prestigious co-author on their paper, or a prestigious university credential.
Science is fundamentally about independent replication, not prestigious citation. By predicating science on this, we can erode the prestige barriers gatekeeping science and open the flood-gates to a more international and intellectually diverse scientific ecosystem — increasing our collective capacity to conjecture, critique and improve on our scientific knowledge.
The transition from analog to digital has been a mess
We did a haphazard job of retrofitting the Internet onto our analog publication ecosystem. Research got scattered and disorganized across hundreds of sites, there’s different tools for publishing work, finding wet lab protocols, flagging fraud, getting help with published research — the list goes on and on.
This mess of tools makes science much less accessible, and it needs to be cleaned up if we want to get more scientists involved in and collaborating on research.
It’s not just experiment artifacts that are hard to access, the current state of the literature and research fields is just as opaque. Scientific papers are merely raw experiment results, and there’s emergent properties of literature like major advances/breakthroughs, gaps in knowledge, debates, refutations, and replications that are typically organized and summarized in review articles. But articles are pre-internet technology, and we can and should create more useful tools like Discourse Graphs and Technology Trees to represent this information.
By making the current state of literature more discoverable, and improving the organization and accessibility of published work, we can improve the transparency of science and open it up beyond the Western-dominant ecosystem that it’s divulged into.
Change the Past to Change the Future
Most researchers and entrepreneurs proposing changes to scientific publication are only looking forward—their ideas apply to new research—but there’s also a lot that can be done to improve our historical record.
It’s common for civilizations to forget or lose access to the knowledge they’ve created, and we should do everything we can to preserve historical research from loss due to censorship and negligence, some of which has already been happening. Decentralized systems like IPFS and Ethereum are the most persistent, immutable, and censorship-resistant storage mechanisms we have, and are the safest way to store historical scientific literature in a lossless medium across time.
There’s also lots of low-quality and non-replicable work polluting our scientific record with noise. If we want to produce research that builds on top of our published literature, we must have a strong foundation to stand on, so our historical literature must have a much more rigorous grounding in truth. From an Information Theory perspective, we need to strengthen the signal to filter out the noise.
We can do this by going back across our published literature and re-opening it for critique, by making research digitally reproducible and enabling scientists and software to go back and ensure that fraudsters and fakes didn’t erroneously get the peer-review “stamp of approval.”
If everybody’s publishing, who’s reviewing?
Too much research gets published and not enough gets read because publications and citations are the predominant measures of scientific contribution. The microeconomic game theory incentivizes researchers to publish instead of reviewing and replicating; there’s no point in publishing work if nobody’s there to critique it.
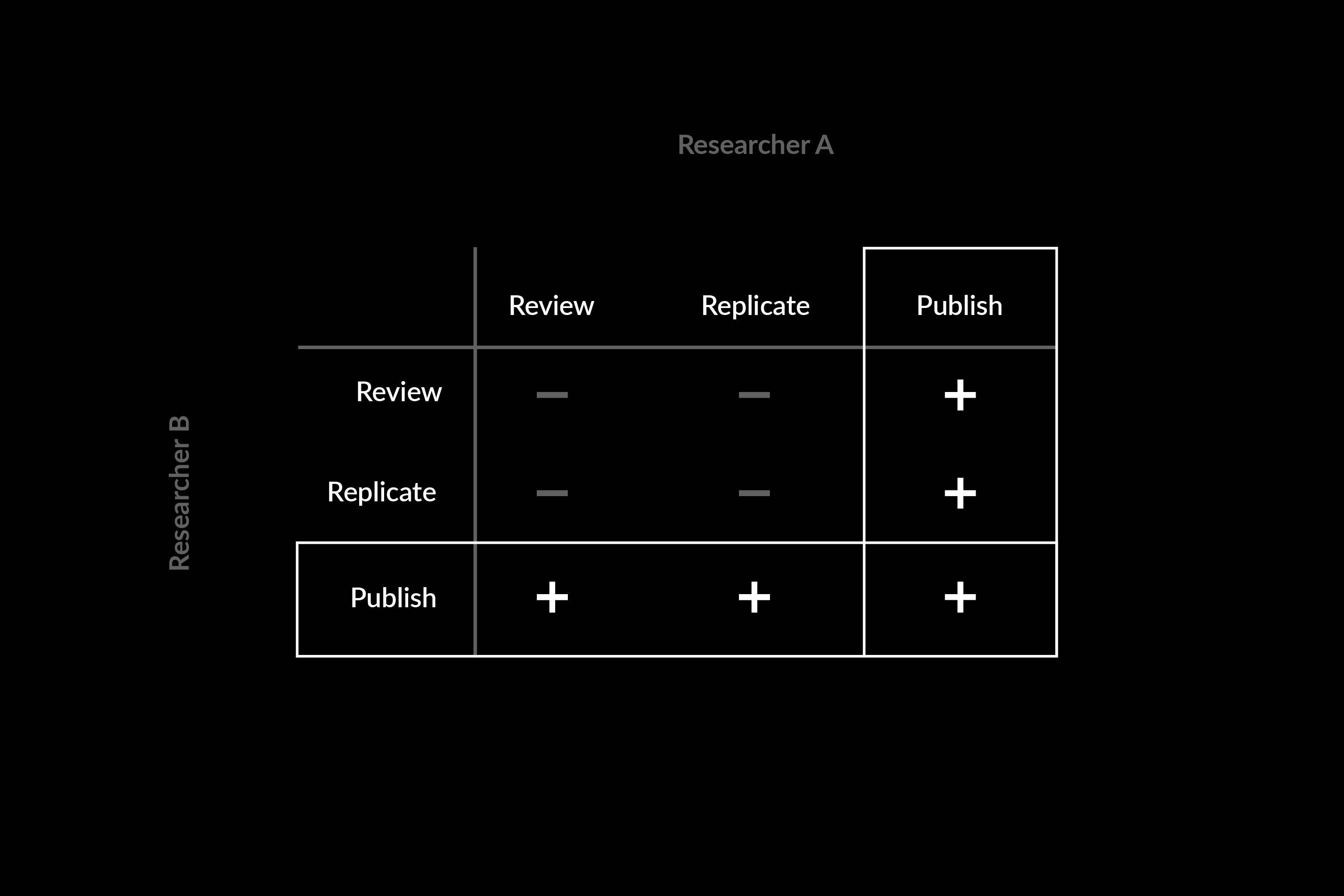
Fundamentally, we want researchers to work on things that usefully contribute to advancing science. But contributing to science doesn’t just involve publishing new positive results, it includes critiquing and replicating the work of peers.
The simple solution is to increase the relative payoff of replicating and reviewing research. This is much easier said that done. But by predicating science on independent replication over prestigious citation, citations as a currency can be replaced—or at least supplemented—with replication and review to tip the scale towards a more equal valuing of conjecture and critique.
Moore’s Law for Science
Software is eating the world, and Moore’s Law manifests itself wherever software and AI take hold. We can position science to benefit from this cone of exponential progress if we make research more machine-readable and remove the gatekeepers preventing software from accessing and using published literature.
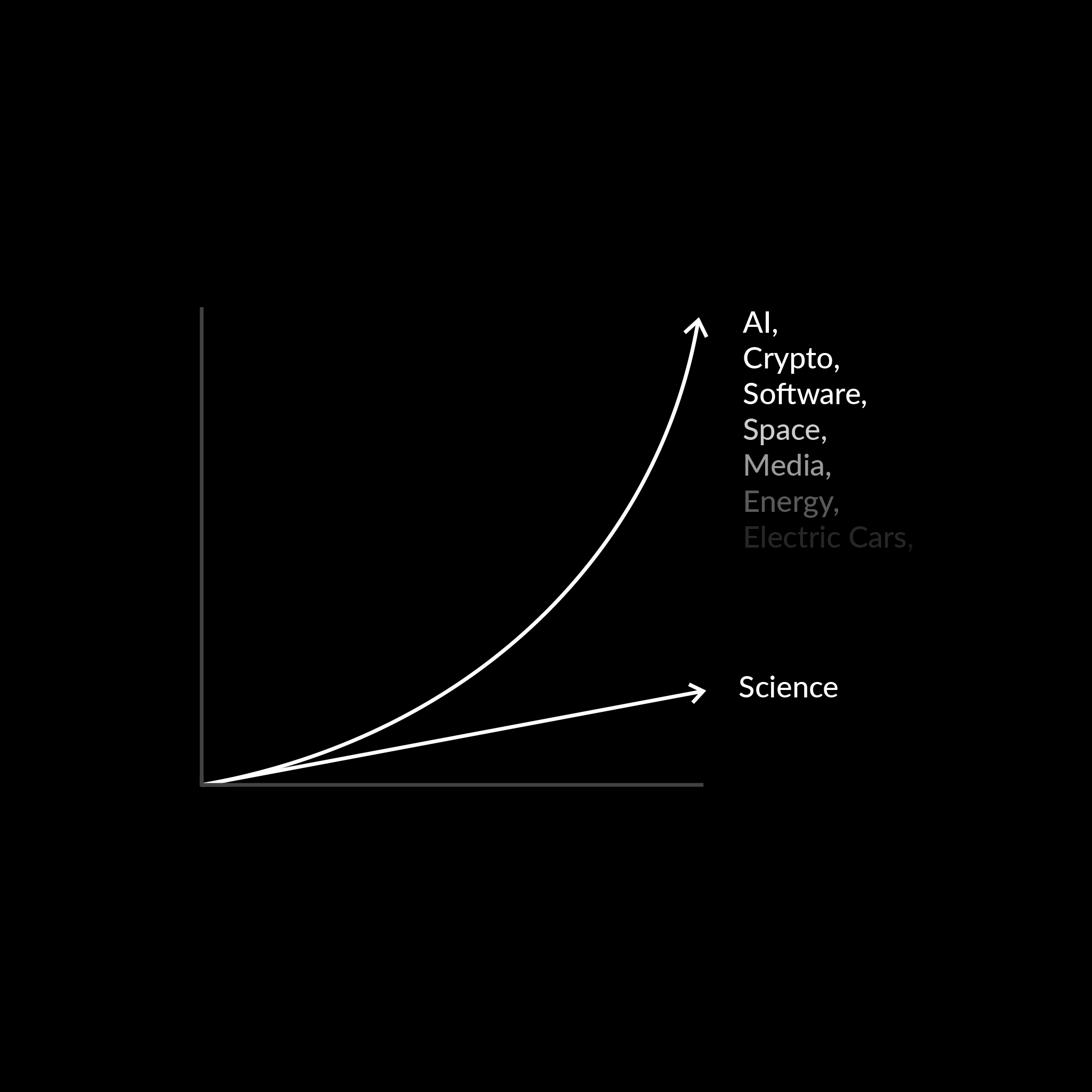
Fundamentally, text-based research papers don’t contain enough information to fully represent our scientific knowledge. Digitally reproducible research means more useful information is available, since the digital artifacts (code and data) are linked for software to use, and AI to be trained on. If done correctly, this could improve the accuracy of scientific AI, and enable the creation of tools that catch issues in research the same way AI catches bugs in software — reducing the risk that we waste decades building on fraudulent work.
A lesser known—but important—fact, is that the paywalls imposed by journals also inhibit a lot of software development. Entrepreneurs struggle to build useful tools for researchers because journals use their monopoly on our scientific record to stifle innovation. An alternate universe where publishers foster an economy of software creators to build on top of the scientific record is obviously superior, and so it should be advocated for and built.
With better software tools, we can outsource the laborious parts of research to machines and free up human capital for the creative work we’re good at — conjecturing and critiquing innovative hypotheses.
The best way to predict the future is to create it
Obviously, there can be practical limitations to some of the ideas here, although there’s clearly room to improve upon research publication to accelerate the rate at which we conjecture, critique and achieve consensus on our knowledge of reality. To do this, we should leverage technology to create an ecosystem that’s more open, collaborative, efficient, and better positioned for the future of the Internet and AI.
We don’t want to just imagine the future, we want to build it. Scholar is applying the ideas in this essay to build a truly reproducible scientific record. Get in touch with us.
Conjecture and criticism are already well known—especially within Deutschian epistemology—but consensus is not discussed as much, so we’ll expand on it a bit. In order for society to agree on what’s scientifically true, we must be able to convince others that our research results are correct. Since, in the limit, we need to convince all of humanity—some of whom trust us and some who don’t—the most scalable mechanism to achieve consensus is to minimize trust assumptions and enable others to independently replicate results. In other words, use a trust-less and mathematically rigorous consensus algorithm for science, much like Bitcoin’s Proof of Work.